Making Progress Toward Open Data: Reflections on Data Sharing at PLOS ONE

Since its inception, PLOS has encouraged data sharing; our original data policy (2003 – March 2014) required authors to share data upon request after publication. In line with PLOS’ ethos of open science and accelerating scientific progress, and in consultation with members of the wider scientific community, PLOS journals strengthened their data policy in March 2014 to further promote transparency and reproducibility.[1] This move was viewed as controversial by many, particularly for PLOS ONE, the largest and most multidisciplinary journal to ever undertake such a mandate. In this post, we look at our experience so far.
In an effort to make data sharing a more integral part of publication and scientific output, PLOS’ data availability policy requires data underlying the results presented in papers to be fully available at time of publication, unless certain restrictions apply. Authors do not necessarily need to share entire primary datasets, but must share the underlying data used to create graphs, figures, and other analyses presented in the paper. Each research article published by PLOS includes a Data Availability Statement (DAS) that describes the location of the data and, if needed, declares any restrictions on making the data publicly available (for example, in cases of limitations due to sensitive data, ethics committee decisions, or the terms of what clinical study participants consented, or did not consent, to release).

This policy, while not always easy to implement, strengthens the scientific record in terms of reproducibility and integrity. Below are some observations from PLOS ONE‘s experience.
Implementation at PLOS ONE
Implementing the data policy at PLOS ONE presented a unique challenge because of the breadth of research published and the large submission volume. It has involved a coordinated effort between internal staff, our Editorial Board, and reviewers. At submission, the staff check each data availability statement to screen for research that simply cannot meet the policy. As manuscripts proceed through the review process, we work with authors, as necessary, to include additional data and information on availability.
We ask our Editorial Board and reviewers to specifically evaluate whether the content of the dataset meets our policy — reviewers must respond to a question in the review form that addresses data policy compliance. When a manuscript reaches acceptance for publication, we systematically check the suitability of the DAS and check for potentially identifying information in datasets from human subjects research. In situations where datasets cannot be shared, we consult the Academic Editor before publication to confirm we are comfortable with the validity of the data restriction and that the manuscript nevertheless meets our publication criteria and standards. In the majority of these situations, we recommend that underlying data be available upon request, ideally via a Data Access Committee or equivalent.
Three years on
PLOS ONE has published over 65,000 papers with a DAS in the three years since the open data policy was put in place. We were initially concerned we would not be able to consider a significant number of submissions because authors could not share data, but this did not turn out to be the case. Since the implementation of the updated policy, we estimate staff have rejected less than 0.1% of submissions due to authors’ unwillingness or inability to share data. What we have seen is a growing acceptance of data sharing and evolution of data sharing practices. For instance, there has been a steady growth in datasets available directly via public data repositories such as the NCBI databases, Figshare or Dryad. While the proportion of articles with a data availability statement linking to one of these repositories is still relatively low, at around 20% in 2016, the growth is encouraging.
Another 60% of articles include data in the main text and supplementary information. While we strongly recommend discipline-specific open repositories where they exist, we also deposit the supporting information files, figures, and tables included with every article to Figshare and give each of these its own DOI. Thus, in addition to being available via the PLOS ONE article, this content is also available through an external data repository. The remaining 20% of papers have data available upon request due to restrictions acceptable under our policy, including restrictions related to sensitive data or because the data are owned by and available from a third party.
Our updated standard has been accompanied by a rise in Academic Editors and reviewers’ comments concerning data sharing and requests for data during the review process. A preliminary analysis of review forms and content of decision letters indicates that comments on data availability have become more frequent, from approximately 18% of submissions just after the policy was implemented in 2014 to 24% in 2016 — this is in addition to the yes/no question in the review form asking reviewers to indicate whether the paper complies with the data policy.
Learned nuances from clinical studies
Initiatives such as the Beau Biden Cancer Moonshot help draw attention to the importance and benefit of sharing clinical data. With a growing number of options and increased support for sharing data from human subjects research [2], we anticipate an increase in the number of these datasets deposited to online repositories. However, clinical data bring additional complexity and a need to consider responsible data sharing. In particular, participant privacy and respect for restrictions included in their informed consent can prevent the public sharing of data. Infrastructures for responsible sharing, such as Data Access Committees for controlled access to sensitive data — for example, those used by dbGaP or the European Genome-phenome Archive — are not yet widely established. Our own experiences indicate that a DAS, at the time of publication, can highlight potential issues, generate constructive discussions on mitigation strategies, and clarify restrictions to readers immediately. (A blog we published last week illustrates some of the benefits of an explicit data availability statement, especially in complex cases such as the one discussed there.)
Impacts and changes in the world of scholarly research
In the period since the strengthened PLOS data policy was announced, the discussion has moved from whether authors should be required to share data to how the data can be most useful and whether authors are providing sufficient data. That’s progress. Other publishers are updating their data sharing policies and requiring a DAS, and funders such as the Bill and Melinda Gates Foundation and Wellcome Trust have implemented policies requiring that data from studies they support be made openly available, with as few restrictions as possible. Government agencies including the National Institutes of Health (NIH), European Medical Association, European Commission and Research Council UK (RCUK) have implemented or are exploring policies that facilitate data sharing. In addition, academic institutions such as Cambridge University provide additional infrastructure and support for researchers to share data. Most recently, the Wellcome Trust, HHMI, and NIH created the Open Science Prize to reward and make public the value of open, shared data.
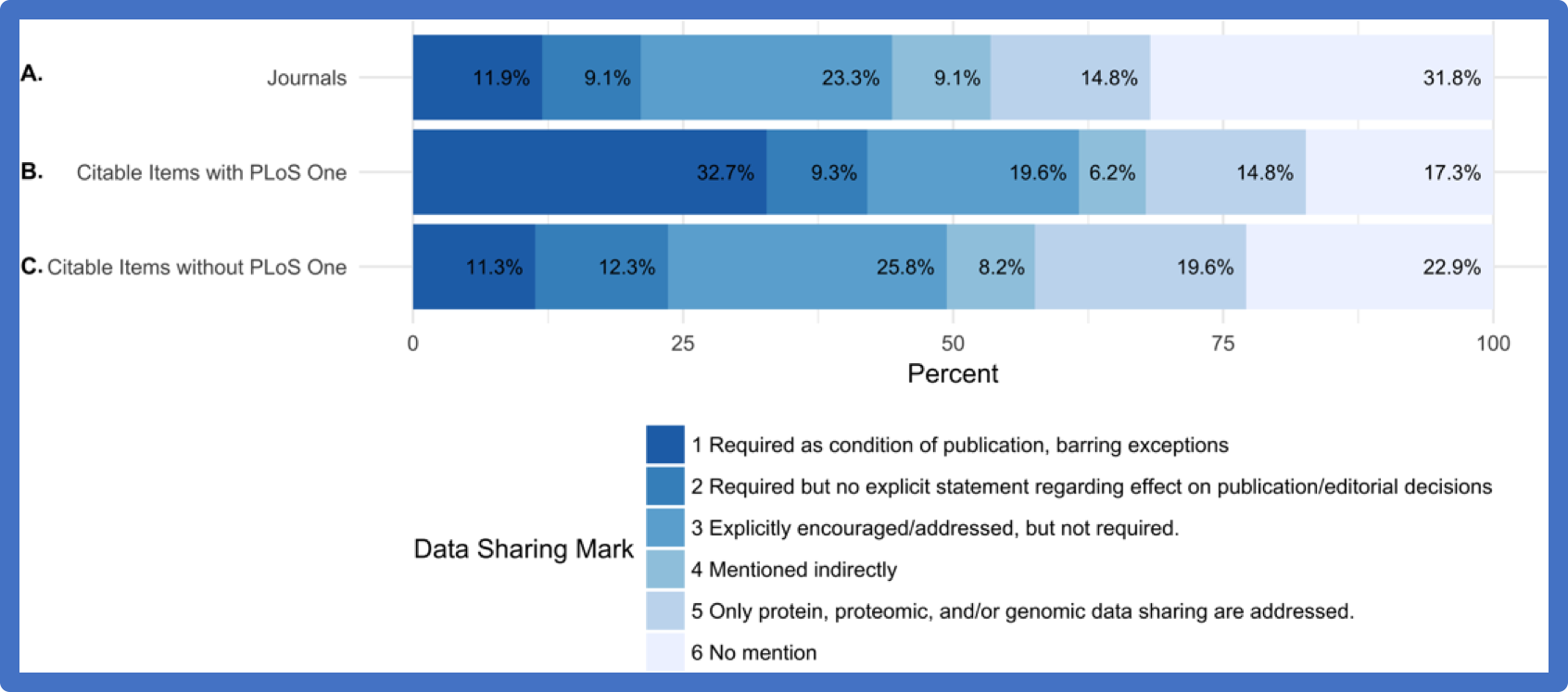
An expectation of data availability is clearly on the upswing among the research community and the public, and PLOS ONE’s adoption of this data policy appears to be having substantial impact on the availability and impact of scientific data. A recent article in PeerJ presents data indicating that the inclusion of PLOS ONE in the analysis dramatically increases the number and proportion of papers for which data sharing is required as a condition of publication in biomedical journals.[3] In parallel, we have seen increasing research submissions studying data sharing. In the PLOS Open Data Collection, we highlight papers that address issues of data sharing in various scientific disciplines and research showing a correlation between publicly available data and increased impact (for example, citation rates). In a similar vein, the PLOS ONE 10-year Anniversary Datasets Collection highlights specific examples of well-reported or widely used datasets.
Ongoing work and future directions
To support efforts to improve data availability and thus the transparency and reproducibility of research and to provide additional guidance to authors, PLOS has taken a number of steps:
- Formed a PLOS Data Advisory Board with broad community representation. With the Board’s assistance, we created the PLOS ONE 10-year Anniversary Datasets Collection and are working to develop discipline-specific guidelines.
- Independently, published guidelines by PLOS Genetics Editors for researchers in the area of genetics and genomics.
- Created an author FAQ that addresses some of the most frequent concerns we encounter, including preparing clinical data for publication so that it is adequately anonymized.
- Provided a list of recommended data repositories, continually updated as we examine new repositories for inclusion. If no specialized community-endorsed open repository exists, we also recommend authors consider university repositories that use open licenses permitting free and unrestricted use.
Of course, there is more work to do and improving data sharing remains a priority for PLOS. To facilitate and improve compliance, we are now focusing on two areas: credit and measurement.
To help credit good data stewardship, we have already adopted the CRediT taxonomy of contributor roles, which allows the recognition of data collection and data curation as contributions made by the author(s), and are requiring an ORCID iD for all corresponding authors to ensure proper attribution. Next, we will be implementing standardized, machine-readable data citations. To this end, we have been working with the Data Citation Implementation Pilot [4] and have participated in a working group (of the Journal Article Tag Suite for Reuse, or JATS4R) for consistent data citation markup and tagging.
We also would like to measure compliance in more meaningful ways. While we systematically check for restrictions in the data availability statements, we do not yet collect overall trends on the adequacy of the data provided. When readers write in to indicate that a dataset is inadequate, we follow up to address the situation; the vast majority of cases are resolved by the authors, either via a note in the article comments or a formal Correction. An early analysis (conducted in 2014 on a small number of papers in a specific discipline) showed full compliance in 40% of the cases compared to 12% prior to the policy implementation. That means that after the policy was implemented, all appropriate datasets were directly available a further 28% of the time. This same study was revisited in 2016, and full compliance had increased to 67% (Tim Vines, personal communication). We are looking at ways to work with the community to better understand and improve these trends.
Conclusions
At PLOS ONE, the implementation of the PLOS Data Policy has been accompanied by a significant increase in the number of papers for which the underlying data can be clearly located and accessed, and we are encouraged by how the community has engaged with us. Reviewers and Academic Editors are considering what data should be available and how it should be shared for manuscripts they assess. And authors, in most cases, are willing to provide the requested data.
This is still a work-in-progress, and we are working with the community – with the many communities that make up PLOS ONE and the other six PLOS journals – to drive improvements toward even broader data availability. Progress, particularly on a large scale, is challenging but with the combined efforts of researchers, other publishers, government organizations, and funding agencies, we are optimistic. We remain committed to a vision of broad and systematic data sharing.
Watch this space for an opportunity to provide feedback on your experience with the PLOS Data Policy, or email us at [email protected].
References
- Bloom T, Ganley E, Winker M (2014) Data Access for the Open Access Literature: PLOS’s Data Policy. PLoS Biol 12(2): e1001797.
- Bertagnolli MM, Sartor O, Chabner BA, Rothenberg ML, Khozin S, Hugh-Jones C, et al. (2017) Advantages of a Truly Open-Access Data-Sharing Model. N Engl J Med 376:1178-1181. http://www.nejm.org/doi/full/10.1056/NEJMsb1702054.
- Vasilevsky NA, Minnier J, Haendel MA, Champieux RE. (2017) Reproducible and reusable research: are journal data sharing policies meeting the mark? PeerJ 5:e3208 https://doi.org/10.7717/peerj.3208.
- Cousijn H, Kenall A, Ganley E, Harrison M, Kernohan D, Murphy F, et al. (2017) A Data Citation Roadmap for Scientific Publishers. bioRxiv (preprint), 100784. http://biorxiv.org/content/early/2017/01/19/100784.
Feature Image Credit: Descrier descrier.co.uk under CC BY 2.0 licence from Flickr