How to publish reusable enzymology data?
In this blog post Carsten Kettner, from the Beilstein-Institut discusses the role STRENDA Guidelines and Database play in helping publish reusable enzymology data.
Even though the idea of a holistic view on biological systems may date back to the work of the Austrian biologist Ludwig von Bertalanffy in the 1950s [1] the emergence of systems biology gained momentum about 20 years ago in the context of the human genome project. However, in order to study biological systems and their complex molecular interactions, it is essential to gain a profound mechanistic understanding supported by high-quality experimental data on detailed single-molecule measurements with individual enzymes. Only detailed data on enzymes enables researchers to create systems-level models of high consistency, and the STRENDA guidelines and STRENDA database have been developed with the aim at supporting progress towards this goal.
Essential information is omitted in the literature
A detailed investigation of the enzymology literature carried out more than 15 years ago [2,3] showed that much of the data published could neither be interpreted nor integrated and reproduced. Recent biomedical literature suggests that this has not significantly improved since: Materials and methods are poorly described, results are not completely presented and there are deficiencies in the use of statistical means and terminology [4,5].
Enzymology data are collected under different experimental conditions, e.g., temperatures, pH, ionic strength, enzyme and substrate concentrations, activators and inhibitors, which make any comparison difficult unless the experimental conditions are fully described. Last year, we examined 11 publications in the biochemistry field in detail, including the Supporting Information, and found at least one omission in every one of the 11 papers – some with severe effects on reproducibility, and others with minor effects [6]. In addition, together with the SABIO-RK team we analyzed the 100 papers (from 2008 to 2018) used for data extraction for the SABIO-RK database (). We observed that the publications often lack information such as unambiguous identifiers for the protein used in the assay and enzyme concentrations. We also found issues with the assay temperature and buffer system used, incomplete biochemistry reactions and inconsistent experimental conditions within the publication [6] which indicates a general problem in data reporting.
Without comprehensive information about the experimental procedure and results, the data cannot be considered reliable and consequently it is not possible to reuse enzyme activity data for future purposes or even reproduce this data.
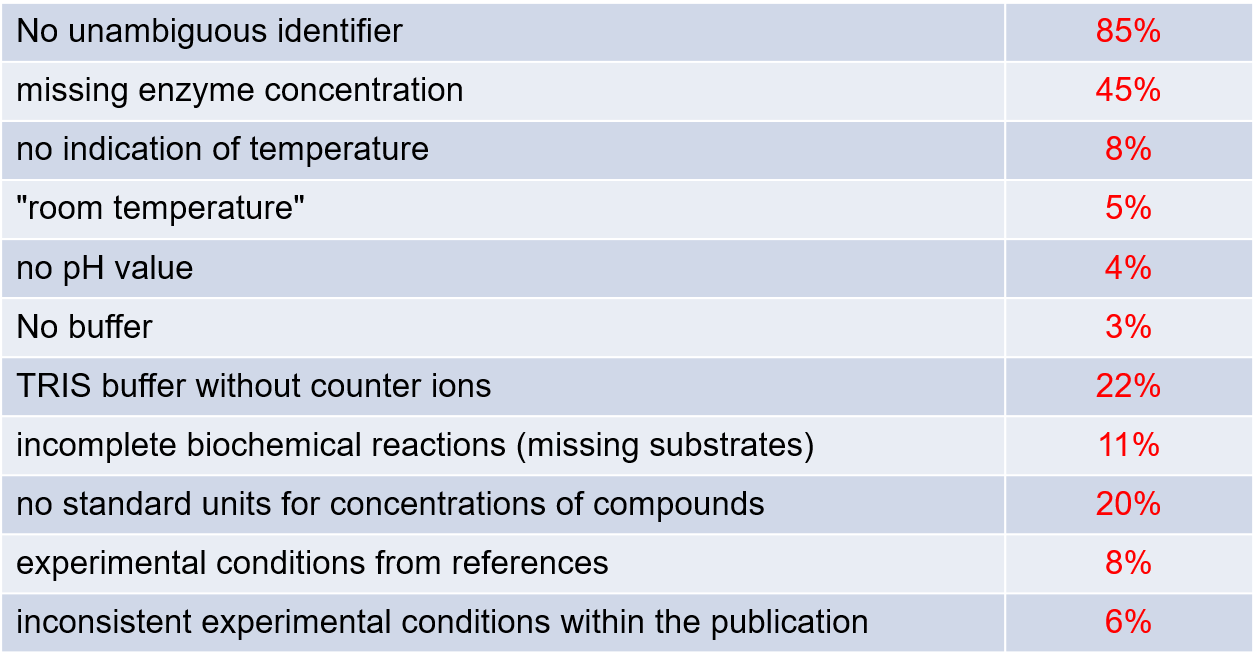
Figure 1 Analysis in SABIO-RK, recent 100 papers (2008-2018), J Biol Chem, Biochemistry, Biochem J, Eur J Biochem, Biochim Biophys Acta, Arch Biochem Biophys, J Bacteriol, FEBS Lett, Plant Physiol, Proc Natl Acad Sci U S A [6] and adapted by data from personal communication.
How to resolve the issue of missing information?
There is no single ideal choice. Some suggest that funding agencies could leverage bonuses and incentives to motivate researchers in spending efforts in reproducible results and data sharing. But this process may take some time. A more promising and faster alternative is providing the community with tools that support both the assessment on comprehensiveness and the delivery of metadata that can be standardized as a minimum set of information to describe the experimental data. Setting standards for minimum information in publications is obviously a bottom-up approach where the community itself develops standards to address the problem of irreproducibility of published data. Such initiatives started over 15 years ago with standards for microarray experiments (e.g., MIAME [7]) and many other disciplines have followed. All these groups share the general principle that standards must be consensus-based, sufficient with regards to the information covered and easy to apply by the researchers [8].
Standards for Reporting Enzymology Data (STRENDA)
Intensive discussions among biochemists and bioinformaticians at a Beilstein workshop in 2003 resulted in the conclusion that standards for reporting minimum information about functional enzyme experiments are urgently needed. In the following year, the STRENDA Commission was founded under the auspices and with support of the Beilstein-Institut. The commission aims at bridging the gap between the effective availability of information in the literature and the requirement to provide all information to allow recipients to understand, interpret and reuse experimental results. The STRENDA Commission consists of an international panel of scientists who are working in diverse fields of enzymology such as enzyme superfamily characterizations, functional protein databases, systems biology, mechanistic enzymology, metabolic control analysis, etc.
Through extensive interactions with the biochemistry community the STRENDA Commission has drawn up the STRENDA Guidelines for reporting enzymology data to ensure that the conditions under which this data were obtained are comprehensively described [9]. The STRENDA Guidelines are reviewed on a regular basis with regards to their practical applicability, and to ensure that they cover current techniques. Today, more than 55 international biochemistry journals, including the PLOS journals, recommend their authors to consult the STRENDA Guidelines when publishing enzyme kinetics data. The guidelines are registered with FAIRsharing.org (DOI:10.25504/FAIRsharing.8ntfwm) and are part of the FAIRDOM Community standards.
Making use of reporting guidelines
Even though the STRENDA Guidelines are widely spread-out and obviously accepted by the scientific community, the Commission recognized that additional effort is required to enforce their use. In order to encourage authors to report in compliance with the guidelines, the Commission incorporated and customized the guidelines in a web-based data acquisition form and database, called STRENDA DB [10]. The acquisition form asks the author who is preparing a manuscript containing enzymology data for the entry of the minimum information on the experiment(s) carried out. Data are automatically assessed against compliance with the guidelines and the user receives warnings when necessary data is missing. This data is defined by the mandatory fields in the acquisition form. If the mandatory fields are completed the description of the experimental data is STRENDA compliant and thus considered complete. After the successful assessment, the data is stored in a database, gets a STRENDA Registry Number (SRN) and is documented in a data report (PDF). This report contains all input data and can be submitted with the manuscript to the journal. In addition, each dataset is assigned a DOI that allows reference and tracking of the data. The data become publicly available in the database only after the corresponding article has been peer-reviewed and published in a journal. It is important to note that neither the STRENDA Guidelines nor STRENDA DB substitute the peer-review process as these tools monitor only the completeness of data sets rather than judging over the quality and soundness of the research findings.

Figure 2 – Concept of STRENDA DB. Data on the protein assayed, experimental conditions and the experimental results are entered in STRENDA DB and automatically assessed on compliance with the STRENDA Guidelines. If information is missing, the user is warned and requested to make additions and/or corrections.
Benefits of using STRENDA DB
Our study of the 11 publications revealed that the use of STRENDA DB could have prevented about 80% of the missing information identified, which demonstrates that computer tools are very well-suited to support authors in ensuring completeness of information. The remaining items falling within the 20% of missing information uncovered will be addressed by subsequent extensions of STRENDA DB [6].
The aim of STRENDA DB is to make the editorial and production process of the manuscript easier and more efficient, with no costs for authors, journals or other users. In particular for journals, STRENDA DB is able to support the journals’ services on improving incoming manuscripts and ensuring that published data is reproducible. The summary report is intended to provide all relevant experimental kinetics data at a glance in order to enable the referees to judge over the soundness and plausibility of the findings. As an increasing number of journals require the authors to submit summary reports STRENDA DB relieves authors from writing this additional document. When submitted together with the manuscript, the journals receive data and metadata that are already formally validated. In addition, the data underlying the characterization of enzymes’ activities are assigned a DOI and stored in the database. STRENDA DB is a recognized data repository and approved by e.g. re3data (https://www.re3data.org/repository/r3d100012329), a service that helps researchers find an appropriate repository for depositing data. Thus, STRENDA DB perfectly fits in the efforts of the PLOS journals to make research data available and to improve the services for authors and readers with regards to research integrity standards (see Jörg Heber’s post and Renee Hoch’s post). In addition, authors contribute to a comprehensive enzyme function data collection that includes enzyme kinetics data along with the experimental conditions applied to obtain these data, STRENDA DB can be queried by the community for this data and thus complements databases such as BRENDA [11] and SABIO-RK [12].
Since its release at the end of 2016, STRENDA DB is recommended as a data assessment and storage tool by more than ten journals, among them The Journal of Biological Chemistry, eLife, Scientific Data and Nature journals, PLOS journals, Archives in Biochemistry and Biophysics and the Beilstein Journal of Organic Chemistry.
The STRENDA Commission is confident that further journal will follow and that STRENDA DB can become a service for the community for enzyme function data comparable to the Protein Data Bank (PDB) for structural biology.
About the Author
 Carsten Kettner studied biology at the University of Bonn and obtained his diploma at the University of Göttingen. In 1999, he was awarded his PhD for his work on the biophysical comprehension of the yeast vacuolar ATPase using the patch-clamp techniques in the group of Adam Bertl at the University of Karlsruhe. As a post-doctoral student he continued both the studies on the biophysical properties of the pump and the investigation of the kinetics and regulation of the plasma membrane potassium channel (TOK1). In 2000 he joined the Beilstein-Institut. Here, he is responsible (a) for the organization of the Beilstein symposia and (b) for the administration and project management of funded research projects. In 2007 he was awarded his certificate of competence as project manager for his studies and thesis from the Studiengemeinschaft Darmstadt (a certified service provider). Since 2004 he coordinates the work of the STRENDA commission and promotes guidelines for reporting enzyme data along with the commissioners (www.strenda.org). These reporting standards have been adopted by, today, about 55 biochemical journals for their instructions for authors and are incorporated in the electronic data validation and storage tool, STRENDA DB. Since 2011, Carsten co-ordinates the MIRAGE project which aims at establishing uniform reporting and representation of glycomics data in publications and which became an essential hub for the development of glycomics infrastructure (www.beilstein-mirage.org). In 2014, Carsten was appointed the head of the funding and conferences department which is also in charge of the foundation’s public relationships.
Carsten Kettner studied biology at the University of Bonn and obtained his diploma at the University of Göttingen. In 1999, he was awarded his PhD for his work on the biophysical comprehension of the yeast vacuolar ATPase using the patch-clamp techniques in the group of Adam Bertl at the University of Karlsruhe. As a post-doctoral student he continued both the studies on the biophysical properties of the pump and the investigation of the kinetics and regulation of the plasma membrane potassium channel (TOK1). In 2000 he joined the Beilstein-Institut. Here, he is responsible (a) for the organization of the Beilstein symposia and (b) for the administration and project management of funded research projects. In 2007 he was awarded his certificate of competence as project manager for his studies and thesis from the Studiengemeinschaft Darmstadt (a certified service provider). Since 2004 he coordinates the work of the STRENDA commission and promotes guidelines for reporting enzyme data along with the commissioners (www.strenda.org). These reporting standards have been adopted by, today, about 55 biochemical journals for their instructions for authors and are incorporated in the electronic data validation and storage tool, STRENDA DB. Since 2011, Carsten co-ordinates the MIRAGE project which aims at establishing uniform reporting and representation of glycomics data in publications and which became an essential hub for the development of glycomics infrastructure (www.beilstein-mirage.org). In 2014, Carsten was appointed the head of the funding and conferences department which is also in charge of the foundation’s public relationships.
References
- Bertalanffy, L. (1950) An Outline of General System Theory. British Journal for the Philosophy of Science 1, p. 114-129.
- Kettner, C. and Hicks, M.G. (2005) The Dilemma of Modern Functional Enzymology. Current Enzyme Inhibition 1(2):3-10.
- Apweiler, R., Cornish-Bowden, A., Hofmeyr; J.-H.S., Kettner, C., Leyh, T.S., Schomburg, D. and Tipton, K.T. (2005) The importance of uniformity in reporting protein-function data. Trends Biochem. Sci. 30:11-12.
- Ioannidis, J.P.A. (2014) How to make more published research true. PLOS Medicine, 11(10):e1001747.
- Vasilevsky, N.A., Brush, M.H., Paddock, H., Ponting, L., Tripathy, S.J., LaRocca, G.M. and Haendel, M.A. (2013). On the reproducibility of science: unique identification of research resources in the biomedical literature. PeerJ, 1:e148; DOI 10.7717/peerj.148.
- Halling, P., Fitzpatrick, P.F., Raushel, F.M., Rohwer, J., Schnell, S., Wittig, U., Wohlgemuth, R., Kettner, C. (2018) An empirical analysis of enzyme function reporting for experimental reproducibility: Missing/incomplete information in published papers. Chem. 242:22-27. doi:10.1016/j.bpc.2018.08.004.
- Brazma, A., Hingamp, P., Quackenbusch, J., Sherlock G., Spellman, P., Stoeckert, C., Aach, J., Ansorge, W., Ball, C.A., Causton, H.C., Gaasterland, T., Glenisson, P., Holstege, F.C.P., Kim, I.F., Markowitz, V., Matese, J.C., Parkinson, H., Robinson, A., Sarkans, U., Schulze-Kremer, S., Stewart, J., Taylor, R., Vilo, J. and Vingron, M. (2001) Minimum information about a microarray experiment (MIAME) – toward standards for microarray data. Genetics, 29:365-371.
- Taylor C.F. et al. (2007) The minimum information about a proteomics experiment (MIAPE). Nat Biotechnol. 25(8):887-893. doi:10.1038/nbt1329
- Tipton, K.F., Armstrong, R.N., Bakker, B.M., Bairoch, A., Cornish-Bowden, A., Halling, P.J., Hofmeyr, J.-H., Leyh, T.S., Kettner, C., Raushel, F.M., Rohwer, J., Schomburg, D., Steinbeck, C. (2014) Standards for Reporting Enzyme Data: The STRENDA Consortium: What it aims to do and why it should be helpful. Sci. 1(1.6):131-137. doi:10.1016/j.pisc.2014.02.012
- Swainston, N., Baici, A., Bakker, B.M., Cornish-Bowden, A., Fitzpatrick, P.F., Halling, P., Leyh, T.S., O’Donovan, C., Raushel, F.M., Reschel, U., Rohwer, J.M., Schnell, S., Schomburg, D., Tipton, K.F., Tsai, M.-D., Westerhoff, H.V., Wittig, U., Wohlgemuth, R. and Kettner, C. (2018) STRENDA DB: enabling the validation and sharing of enzyme kinetics data. The FEBS J. 285(12):2193-2204. doi:10.1111/febs.14427.
- Jeske L., Placzek S., Schomburg I., Chang A., Schomburg D. (2019) BRENDA in 2019: a European ELIXIR core data resource. Nucleic Acids Res., in print (2019).
- Wittig, U., Kania, R., Golebiewski, M., Rey, M., Shi, L., Jong, L. Algaa, E., Weidemann, A., Sauer-Danzwith, H., Mir, S., Krebs, O., Bittkowski, M., Wetsch, E., Rojas, I., Müller, W. (2014) SABIO-RK – database for biochemical reaction kinetics. Nucleic Acids Research, 40 (Database issue):D790-6 (2014). http://nar.oxfordjournals.org/content/40/D1/D790